
1. 자료구조의 큰 구림
- 시간 복잡도 : 입력의 크기에 따른 프로그램 실행 시간의 관계
- 빅오 표기법 : 함수의 점근적 상한을 표기하는 방법 (입력에 따른 실행 시간의 점근적 상한)
시간 복잡도빅오 표기설명
| 상수 시간 | O(1) | 입력 크기와 무관하게 항상 일정한 시간이 걸림. |
| 로그 시간 | O(\log n) | 입력 크기가 커질수록 처리 시간이 천천히 증가 (이진 탐색 등). |
| 선형 시간 | O(n) | 입력 크기에 비례하여 시간이 증가. |
| 로그 선형 시간 | O(n \log n) | 선형 증가 + 로그 증가가 결합된 형태 (합병 정렬, 퀵 정렬 등). |
| 이차 시간 | O(n^2) | 중첩된 반복문으로 인해 시간이 제곱 형태로 증가 (버블 정렬 등). |
| 삼차 시간 | O(n^3) | 세 개의 중첩 반복문 등으로 시간이 세제곱 형태로 증가. |
| 지수 시간 | O(2^n) | 입력 크기가 커질수록 시간이 매우 빠르게 증가 (브루트포스 알고리즘 등). |
| 팩토리얼 시간 | O(n!) | 입력 크기만큼 순열 조합을 계산하는 알고리즘 (외판원 문제 등). |

2. 배열과 연결 리스트
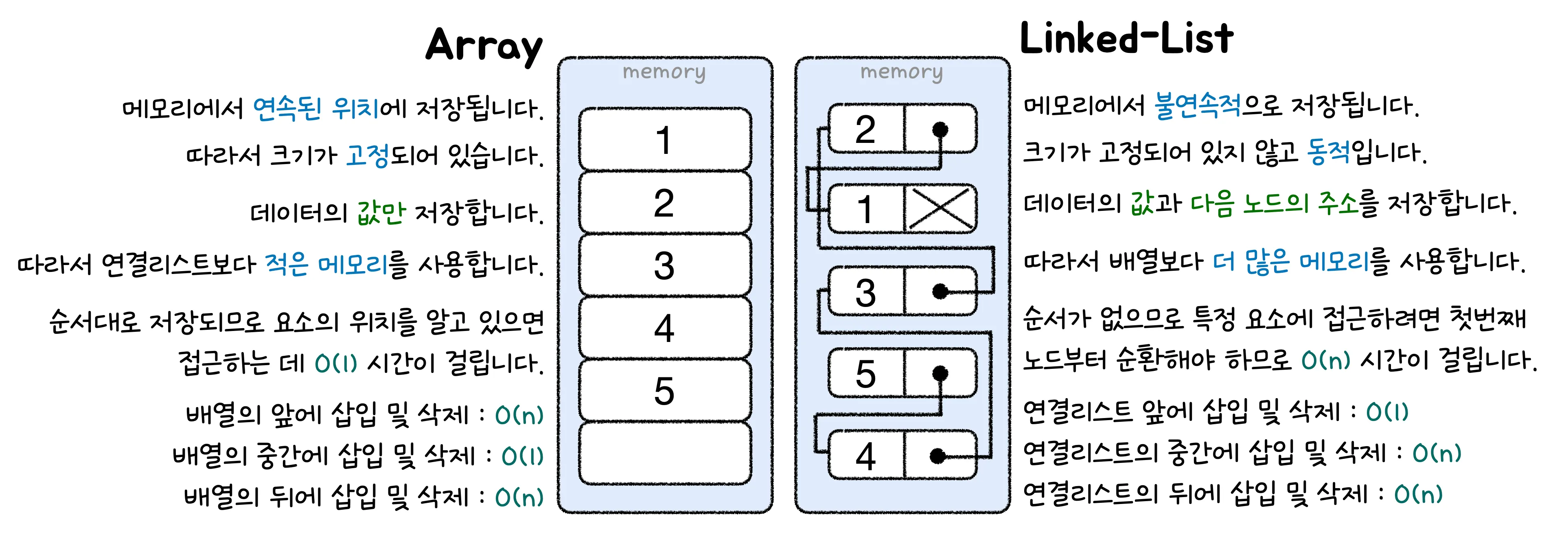
배열 : 일정한 메모리 공간을 차지하는 여러 요소들이 순차적으로 나열된 자료구조
- 인덱스(index) : 데이터에서 검색 성능을 향상시키기 위해 테이블의 특정 컬럼에 대해 생성하는 데이터 구조인덱스를 통해 접근 및 수정만 하는 경우도 O(1)
- 배열의 시간 복잡도는 O(n)이다. (특정 인덱스로의 탐색, 삽입, 삭제가 수행될 때 반복적으로 요소를 확인하거나 이동하기 때문. + 배열의 중간에 삽입 및 삭제하면 O(1) )
연결 리스트(linked list) : 노드의 모음으로 구성된 자료구조
- 특정 요소에 접근할 때는 앞에서부터 순차적으로 접근하기 때문에 O(n)
- 새로운 노드를 삽입 혹은 삭제하는 경우 재정렬이 불필요하기 때문에 O(1)노드(node) : 저장하고자 하는 데이터와 다음 노드의 위치 정보를 구성하는 단위
- 특정 노드에 접근한다면, 다음 노드의 위치도 알 수 있기 때문에 자연스럽게 이어서 다음 노드의 데이터에도 접근 가능. (연결 리스트의 첫 번째 노드를 헤드, 마지막 노드를 꼬리라고 부른다.
특징으로는 연속적으로 구성되어 있는 데이터를 불연속적으로 저장할 수 있다.
- ⇒ 노드에는 다음 노드가 어디에 있는지를 가리키는 정보를 포함되어 있기 때문

3. 스택과 큐
- 스택(stack) : 한 쪽에서만 데이터의 삽입 및 삭제가 가능한 자료구조로 Last In First Out을 뜻하는 후입선출(LIFO) 구조로 불린다.
- 푸시(push) : 스택에 데이터를 저장하는 연산
- 팝(pop) : 스택에서 데이터를 빼내는 연산 (스택에서 제거함과 동시에 반환 값이 존재)
- 스택 자료구조가 활용될 수 있는 상황
- 이력서를 임시 저장하고 가장 최근 내역을 활용할 때
- 뒤로가기 기능을 만들 때 (가장 마지막에 방문한 사이트가 첫 번째 뒤로가기 대상이 됨)
- 큐(queue) : 한 쪽으로 데이터를 삽입하고, 다른 한쪽으로 데이터를 삭제할 수 있는 자료구조로 First In First Out을 뜻하는 선입선출(FIFO) 구조로 불린다.
- 인큐(enqueue) : 큐의 한 쪽 끝에 데이터를 삽입하는 연산
- 디큐(dequeue) : 한 쪽 끝으로 데이터를 빼내는(삭제하는) 연산
- 원형 큐(circular queue)
데이터를 삽입하는 쪽과 삭제하는 쪽, 양쪽을 하나로 연결해 원형으로 사용하는 자료구조 데이터 삽입, 삭제 시 인덱스가 점점 뒤로 밀리면서 앞에 있던 공간을 사용하지 못하는 선형 큐의 문제점을 보완
원형 큐 구현 시 포화상태를 처리하기 위해 % 연산자를 활용 front == (rear+1) % MAX_QUEUE_SIZE

2. 덱(deque)
양쪽으로 데이터를 삽입/삭제 할 수 있는 큐

3. 우선순위 큐(priority queue)
저장된 요소들이 선입선출이 아닌 정해진 우선순위에 맞춰 처리되는 큐 (Heap 이라는 자료구조를 기반으로 구현되는데, 이를 이해하려면 트리가 무엇인지 이해해야함.)

4. 해시 테이블
- 해시 테이블(hash table) : 키와 값의 대응으로 이루어진 표(테이블)와 같은 형태의 자료구조
- key - 해시 테이블에 대한 입력 (Ex. 이름)
- value - 키를 통해 얻고자 하는 데이터 (Ex. 전화번호)
⇒ 매우 빠른 검색 속도를 가지고 있다. 일반적인 상황에서 해시 테이블을 활용한 검색, 삽입, 삭제 연산의 시간복잡도는 O(1)이다. 그러나 메모리 공간이 많이 소모된다.
해시 테이블의 구조와 동작
- 키를 통해 얻고자 하는 데이터 → 버킷(bucket)에 저장.
- 버킷은 여러 개가 존재하며, 배열을 형성한다.
- 해시 함수는 키를 인자로 활용해 인덱스를 반환
- 반환된 인덱스 = 버킷 배열의 인덱스
⇒ 키를 해시 함수에 통과시켜 원하는 버킷에 접근하는 것
- 해시 함수(hash function) : 임의의 길이를 지닌 고정된 길이의 데이터로 변환하는 단방향 함수
⇒ 특정 입력 데이터를 고정된 길이의 해시 값으로 변환할 때 사용됨 - 해시 알고리즘 : 해시 함수의 연산 방법 (다양한 알고리즘 존재)
⇒ 해시 함수는 무작위 값을 만들거나 단방향 암호를 만들 때, 데이터의 무결성을 검증하기 위해 사용되기도 한다.
웹 프레임워크에서 비밀번호를 비롯한 개인정보 저장에 활용되는 해시 함수를 지원하는 경우가 많다.
해시 충돌(hash collision) : 서로 다른 키에 대해 같은 해시 값이 대응되는 상황
해시 충돌 해결 방안 2가지
- 체이닝(chaining)
충돌이 발생한 데이터를 연결 리스트로 추가하는 방법으로, 서로 다른 키가 같은 위치로 해시되어도 단순히 연결 리스트의 노드가 추가됨. (충돌이 발생할 때마다 연결 리스트의 노드가 추가된다면 빠른 속도를 가진 해시 테이블의 장점을 살리지 못할 수 있다.) - 개방 주소법(open addressing)
충돌이 발생한 버킷의 인덱스가 아닌 다른 인덱스에 데이터를 저장하는 방법. ( = 자리 없는 인덱스를 피해 다른 인덱스를 알아보자)
다른 버킷의 인덱스를 찾는 과정을 조사(probe)라고 함.
선형 조사법 : 충돌이 발생한 인덱스의 다음 인덱스부터 순차적으로 가용 가능한 인덱스를 찾아 나서는 방법, 그러나 충돌이 발생한 인덱스 인근에 데이터가 몰려 저장될 수 있다. 이러한 현상을 군집화(clustering)라고 한다.
'Computer Science' 카테고리의 다른 글
| [CHAPTER - 03] 운영체제 - 2 (0) | 2025.11.15 |
|---|---|
| [CHAPTER - 03] 운영체제 - 1 (0) | 2025.11.13 |
| [CHAPTER - 02] 컴퓨터구조 - 2 (0) | 2025.11.12 |
| [CHAPTER - 02] 컴퓨터 구조 - 1 (0) | 2025.11.10 |