
NoSQL의 등장 배경
소프트웨어의 핵심은 데이터이며, 올바른 저장소 선택은 성능·확장성·신뢰성과 직결된다. 모놀리틱에서 마이크로서비스로의 전환과 함께 데이터 저장소도 새로운 요구를 맞추며 발전해왔다. 1장에서는 이러한 아키텍처 변화와 데이터 저장소의 현재 과제를 다룬다.
모놀리틱 아키텍처

- 작은 프로젝트에서는 운영하기 쉽지만, 규모가 커지면 유지보수 복잡도가 증가
- 한 모듈의 문제나 수정이 전체 시스템 장애 및 재배포로 이어짐
- 대량 트래픽·복잡한 트랜잭션 대응이 어렵고, 프레임워크·언어 변경이 전체 애플리케이션에 영향을 끼침
- 부분 확장이 불가능해 리소스 낭비와 업데이트 지연이 발생
마이크로서비스 아키텍처
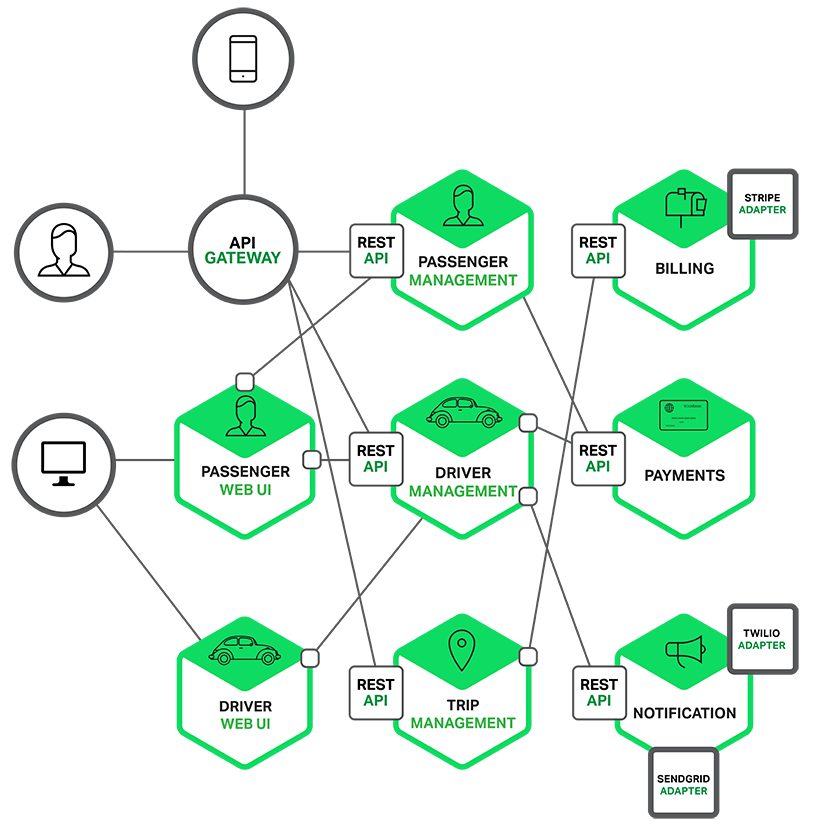
- 새로운 기능 추가와 배포가 편리하고, 특정 서비스만 독립적으로 확장할 수 있어 민첩하고 유연함
- 서비스별로 다양한 개발 도구를 선택할 수 있고, 서비스 간 독립성으로 안정성이 높음
- 분리로 인한 관리 복잡도와 운영 부담이 커져, 모든 상황에 항상 적합한 설계는 아님
데이터 저장소 요구 사항의 변화
- 과거 모놀리틱 서비스에서는 관계형 데이터베이스(RDBMS)가 가장 널리 사용되었다.
- 구조화된 데이터와 정형 쿼리 처리에 강점이 있어 안정적인 트랜잭션 관리와 데이터 무결성을 보장할 수 있었다.
- 최근 트렌드는 비정형 데이터의 증가
- 시계열 데이터, 로그, JSON, 이미지, 센서 데이터 등 다양한 형식의 데이터가 빠르게 늘어나고 있다.
- 이러한 데이터는 RDBMS에서 처리하기 어렵거나, 스키마 변경이 빈번하면 개발 속도가 느려질 수 있다.
- NoSQL 데이터베이스의 활용 증가
- 필요할 때 유연하게 데이터 구조를 변경 가능 → 빠른 개발과 반복적인 기능 추가에 유리하다.
- 확장성(Scale-out)과 다양한 데이터 모델(문서, 키-값, 그래프, 컬럼 패밀리 등)을 지원하여 현대 애플리케이션의 요구 사항을 충족한다.
NoSQL이란?
전통적인 관계형 데이터베이스(RDBMS)와 달리, 스키마가 자유롭거나 비정형 데이터를 처리할 수 있는 데이터베이스
NoSQL의 일반적인 특징
- 실시간 응답
- 연구에 따르면 100ms 이상 지연이 발생하면 사용자가 느낄 수 있음
- 따라서 데이터 저장소는 대부분의 트랜잭션에서 0~1ms 수준의 지연을 유지해야 함
- 확장성(Scalability)
- 예상치 못한 이벤트나 트래픽 급증 시에도 트랜잭션 처리량을 유연하게 확장할 수 있어야 함
- 수평적 확장(서버 추가)과 수직적 확장(리소스 증설) 모두 고려
- 고가용성(High Availability)
- 장애 상황에서도 데이터 접근이 끊기지 않아야 함
- 복제, 장애 복구, 페일오버 등을 통해 항상 사용 가능한 상태를 유지
- 클라우드 네이티브(Cloud Native)
- 클라우드 제공 업체에서 DBaaS(Database as a Service) 형태로 제공
- 직접 설치·운영 없이, 바로 서비스를 이용 가능 → 관리 부담 감소
- 단순성(Simplicity)
- 서비스별로 요구 사항에 맞는 적절한 데이터 모델 선택이 권장됨
- Ex. JSON 문서, 키-값, 시계열 데이터 등
- 유연성(Flexibility)
- NoSQL은 다양한 형식의 비정형 데이터를 저장할 수 있음
- 데이터 구조 변경이나 새로운 데이터 타입 추가가 비교적 자유로움
NoSQL 데이터 저장소 유형
대표적인 데이터 저장 방식의 각 저장 유형별 특징과 사용 사례에 대해 알아보자
그래프 유형

- 엔티티 간의 관계를 효율적으로 저장하도록 설계
- 노드(node), 에지(edges), 속성(properties)
- 노드: 데이터의 엔티티
- 에지: 데이터 사이의 관계
- 추천 서비스, 사기 감지, 소셜 미디어, 네트워크 및 IT 운영 등의 상황에서 유용함
칼럼 유형

- 행(row)이 아닌 열(column)을 기준으로 저장
- 데이터는 하나의 열에 중첩된 키-값 형태로 저장됨 (유연한 스키마 가능)
- 데이터 웨어하우스, 분석, 보고, 빅데이터 처리에 적합함
- Ex. Apache Cassandra, HBase
문서 유형

- 데이터를 JSON과 유사한 형태로 저장해 개발자가 직관적으로 다루기 쉬움
- 모든 데이터는 키-값 쌍으로 구성된 문서(document)이며 계층적 트리 구조를 가짐
- 스키마가 유연해 새로운 필드 추가나 구조 변경이 자유로워 빠른 개발에 적합
- 데이터 저장 및 검색이 효율적이며 특히 비정형 데이터 처리에 강점을 가짐
- Ex. MongoDB, CouchDB, AWS DocumentDB
키-값 유형

- 가장 단순하면서도 빠른 형태의 데이터 저장소
- 모든 데이터는 고유한 키(key)와 그에 대응하는 값(value)으로 저장되며 키 자체가 의미 있는 데이터로 사용됨
- 키를 통해 값을 즉시 검색할 수 있고 키를 삭제하면 연결된 값도 함께 제거됨
- 단순 구조 덕분에 매우 빠른 데이터 접근 속도와 처리 성능을 제공
- Ex. Redis, AWS ElastiCache, AWS DynamoDB, Oracle NoSQL Database, Memcached
레디스란?
고성능의 키-값 기반 인메모리 NoSQL 데이터베이스로, 오픈 소스 기반으로 개발된 데이터 저장소이다.
레디스의 특징
- 실시간 응답 : 메모리 기반 저장으로 매우 빠른 성능 제공
- 단순성 : 키-값 구조와 다양한 자료구조 지원
- 고가용성 : 복제와 장애 조치로 안정적 운영 가능 (HA)
- 확장성 : 클러스터링을 통한 수평 확장 용이
- 클라우드 네이티브 : 주요 클라우드에서 관리형 서비스로 사용 가능
High Availability (HA) : 서버 장애나 네트워크 문제 같은 상황에서도 Redis 서비스를 중단 없이 사용할 수 있도록 하는 기능
- 복제(Replication) : Master-Replica 구조로 데이터를 여러 노드에 복제 → Master 장애 시 Replica가 데이터 유지
- 자동 장애 조치(Failover) : Sentinel 같은 모듈이 Master 장애를 감지하고 Replica를 자동으로 새 Master로 승격
- 클러스터링(Clustering) : 데이터를 여러 노드에 분산 저장 → 일부 노드가 죽어도 전체 서비스는 계속 동작
→ 단일 장애점(Single Point of Failure, SPOF)을 없애고, 안정적으로 Redis를 운영할 수 있게 해주는 메커니즘
마이크로서비스 아키텍처와 레디스
MSA에서 Redis가 어떻게 활용될 수 있는지 알아보자.
데이터 저장소로서의 레디스
- 설치가 간단하고, 최소한의 리소스로도 높은 처리량을 낼 수 있음
- 문자열, 해시, 리스트, 집합(Set), 정렬된 집합(Sorted Set) 등 다양한 자료 구조 제공
- 데이터는 AOF(Append Only File) 또는 RDB(Snapshot) 방식으로 디스크에 주기적으로 저장 가능 → 장애 시 데이터 복구 가능
메시지 브로커로서의 레디스
- Pub/Sub 기능: 가장 단순한 메시징 기능으로 매우 빠르게 동작하며 손쉽게 사용할 수 있음
- Fire-and-Forget 패턴이 필요한 간단한 알림 서비스에서 특히 유용
- List 자료 구조: 데이터를 빠르게 push/pop 할 수 있으며 애플리케이션은 대기하다가 새로운 데이터가 들어오면 블로킹 기능으로 즉시 읽을 수 있음
- Stream 자료 구조: Redis를 완전한 스트림 플랫폼으로 활용 가능
- 데이터는 append-only 방식으로 계속 추가됨
- 분산 처리가 가능
- 저장된 데이터를 시간대별로 조회할 수 있음
'Study Notes > 개발자를 위한 레디스' 카테고리의 다른 글
| [개발자를 위한 레디스] 6장 레디스를 메시지 브로커로 사용하기 (0) | 2025.11.15 |
|---|---|
| [개발자를 위한 레디스] 5장 레디스를 캐시로 사용하기 (0) | 2025.11.10 |
| [개발자를 위한 레디스] 4장 레디스 자료 구조 활용 사례 (0) | 2025.11.03 |
| [개발자를 위한 레디스] 3장 레디스 기본 개념 (1) | 2025.10.11 |
| [개발자를 위한 레디스] 2장 레디스 시작하기 (2) | 2025.08.27 |