
Redis는 다양한 자료구조와 빌트인 명령어를 통해 데이터를 애플리케이션으로 가져와 처리하는 시간을 줄이고, 짧은 대기 시간으로 대량의 작업을 효율적으로 처리할 수 있다.
sorted set을 이용한 실시간 리더보드

리더보드는 기본적으로,
- 사용자의 증가에 따라 가공해야 할 데이터가 몇 배로 증가한다.
- 데이터가 실시간으로 반영되어야 한다.
- 여러 가지 수학적 계산이 빠르게 수행되어야 한다.
sorted set
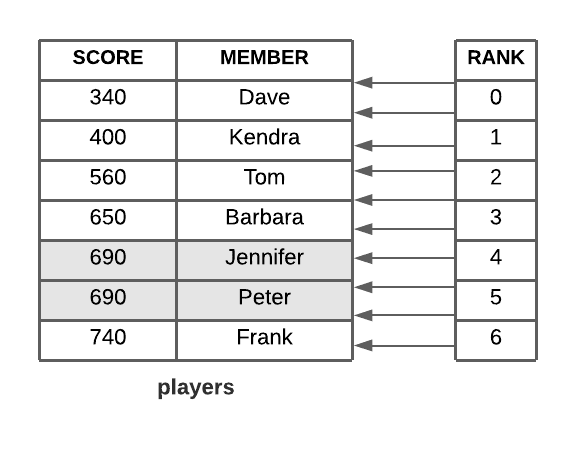
- 레디스의 sorted set에서 데이터는 저장될 때부터 정렬되어 들어간다.
데이터 저장 및 조회
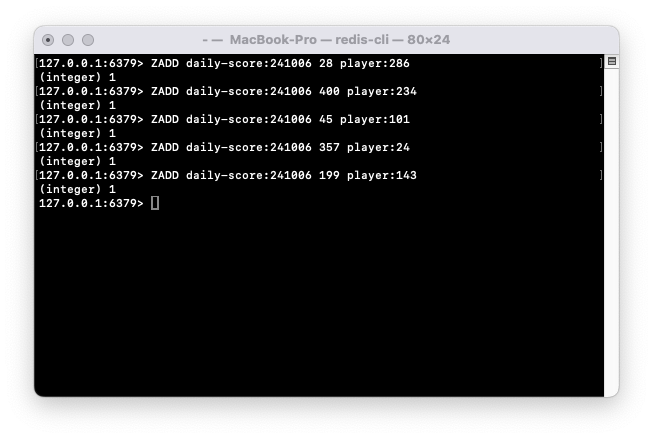
- ZADD 커맨드를 활용해서 데이터(스코어, 플레이어 번호)를 저장한다.

- ZRANGE를 활용해서 스코어 낮은 순서로 데이터를 조회할 수 있다.
- ZREVRANGE를 활용해서 상위 스코어 N개 데이터를 조회할 수 있다.

- ZADD를 활용해서 기존 플레이어의 점수 데이터 업데이트가 가능하다.
- set 자료구조는 기본적으로 데이터의 중복을 허용하지 않는다.

- ZINCRBY를 활용해서 스코어 데이터의 증감도 가능하다. (증감 후 데이터 재정렬)
랭킹 합산

- 주간 리더보드는 매주 월요일마다 초기화된다고 가정한다. 예를 들어 기준 날짜가 2024년 10월 2일(화)라면, 2024년 9월 30일(월)부터 10월 2일(화)까지의 점수를 합산한 결과가 필요하다.
- 이때 Redis의 ZUNIONSTORE 명령어를 활용하면, 여러 날짜의 데이터를 손쉽게 합산하여 주간 리더보드를 생성할 수 있다.

- 실제로 커맨드를 활용하여 데이터를 합산하는 과정
- weekly-score:2410-1을 확인해보면 합산된 데이터 순서로 정렬되어 있다.
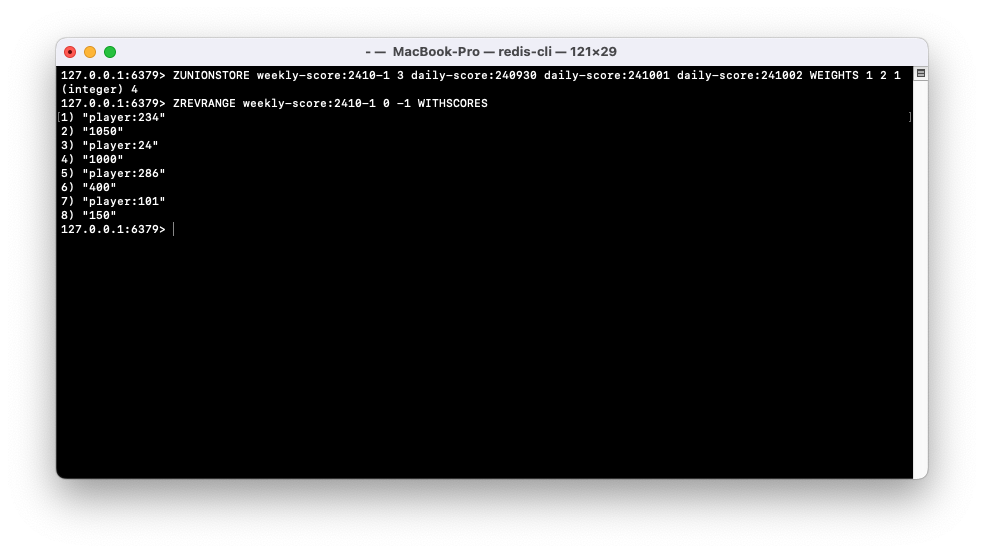
- weights를 활용하여 특정한 날(키)에 가중치를 줄 수도 있다.
sorted set을 이용한 최근 검색 기록
검색 기록의 요구사항은 다음과 같다.
- 유저별로 다른 키워드 노출
- 검색 내역은 중복 제거
- 가장 최근 검색한 5개의 키워드만 사용자에게 노출

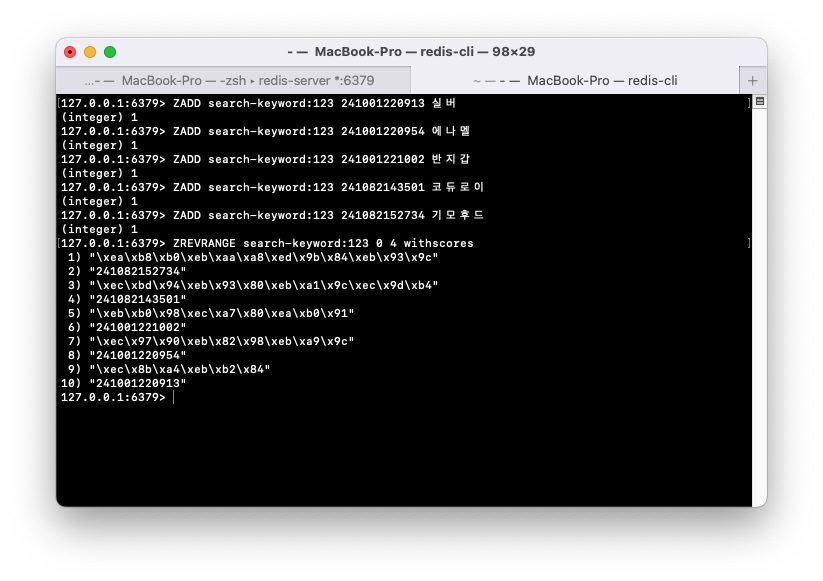
- 실제 데이터를 저장하고, 최근 5개 데이터를 조회할 수 있다.
- 같은 키워드로 검색해도 중복되지 않는다. (set 자료구조 특징)
- 데이터를 저장(ZADD)할 때마다 음수 인덱스 -6번째를 삭제하는 로직을 추가하면 실시간으로 데이터 5개를 유지하며 삭제할 수 있다.
sorted set을 이용한 태그 기능
- 데이터베이스에서 태그 기능을 사용하려면 최소 두 개의 테이블이 필요하다.
- 태그 테이블 – 태그 정보를 저장
- 태그-게시물 테이블 – 게시물과 태그 간의 관계를 연결
- Redis에서는 SET 명령어를 사용하면 게시물의 태그 기능을 매우 간단하게 구현할 수 있다.

- 게시글 id를 기준으로 태그 추가

- 태그를 기준으로 게시글을 추가

- SMEMBERS 커맨드를 이용하여 특정 태그를 가지고 있는 포스트를 쉽게 확인할 수 있다.

- SINTER 커맨드를 이용하여 특정 Set의 교집합을 확인함으로써 IT, DataStore라는 두 태그를 공통으로 가지고 있는 포스트의 ID를 확인할 수 있다.
랜덤 데이터 추출
- 레디스를 사용하면 O(1)의 시간 복잡도를 이용해 랜덤한 데이터를 추출할 수 있다. (RANDOMKEY 커맨드 활용)
- hash: HRANDFIELD 커맨드 활용
- set: SRANDMEMBER 커맨드 활용
- sorted set: ZRANDMEMBER 커맨드 활용
레디스에서의 다양한 카운팅 방법
좋아요 처리하기

- 댓글 id를 기준으로 set을 생성한 뒤, 좋아요를 누른 유저의 id를 set에 저장하면 중복 없이 데이터를 저장할 수 있다.
- 각 댓글별로 좋아요를 누른 수는 SCARD 커맨드로 확인할 수 있다.
읽지 않은 메시지 수 카운팅하기
- 메시지가 도착할 때마다 관계형 DB를 바로 업데이트하지 않고 Redis와 같은 인메모리 데이터베이스에 일시적으로 저장한 뒤, 필요한 시점에 한꺼번에 DB에 반영하면 부하를 최소화하고 성능을 향상시킬 수 있다.

Redis의 Hash 구조를 이용하면 각 사용자의 채널별 메시지 개수를 효율적으로 관리할 수 있다.
- 새 메시지를 수신하면 HINCRBY user:<userId> channel:<channelId> 1 명령으로 카운트를 증가시킴
- 메시지가 삭제되면 HINCRBY user:<userId> channel:<channelId> -1 명령으로 값을 감소시킴
- Hash 구조를 활용하여 간단하고 빠르게 사용자 식별 → 채널 선택 → 데이터 업데이트 작업을 수행
DAU 구하기
DAU(Daily Active User) : 하루 동안 서비스에 방문한 사용자의 수
레디스의 비트맵(Bitmap)을 활용하면 메모리를 효율적으로 사용하면서 실시간으로 서비스의 DAU(Daily Active Users)를 집계할 수 있다
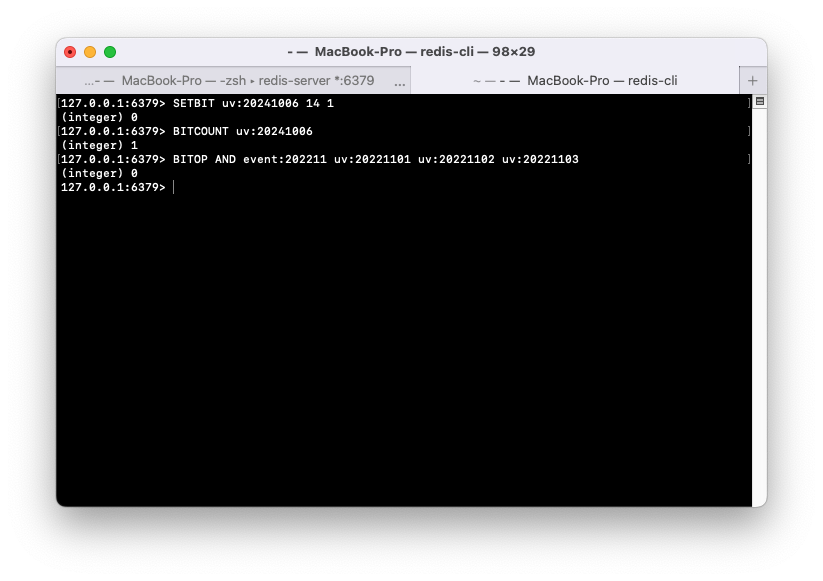
- SETBIT: 특정 날짜의 방문한 사용자 ID에 해당하는 비트를 1로 설정하여 방문 기록을 표시
- Ex. 2024년 10월 6일, id가 14인 유저가 접근했을 때 오프셋 14를 1로 설정
- BITCOUNT: 해당 날짜에 방문한 사용자 수 집계
- BITOP AND: 여러 날짜에 연속 방문한 사용자 집계, 특정 기간 동안 매일 출석한 사용자 확인 가능
- 정보들을 새로운 비트맵 자료 구조에 저장할 수 있고, 리스트로 변환하여 확인할 수도 있다.
hyperloglog를 이용한 애플리케이션 미터링
- 미터링 솔루션은 사용자의 서비스 사용 내역을 기반으로 동작하므로 대용량 데이터를 효율적으로 처리할 수 있어야 한다.
- 다음 조건을 만족할 경우 HyperLogLog를 사용한다.
- 집합 내 유일한 데이터의 개수를 카운팅해야 할 때
- 1% 미만의 오차는 허용할 때
- 카운팅할 때 사용한 정확한 데이터를 다시 확인할 필요가 없을 때
- HyperLogLog는 set과 비슷하게 동작하지만, 저장되는 용량이 12KB로 고정되어 있어 메모리를 효율적으로 사용할 수 있다.
- PFMERGE를 사용하면 여러 개의 HyperLogLog 데이터를 합쳐서 집계할 수 있다.
- PFMERGE 2024:user:245 202410:user:245 202411:user:245 202412:user:245

- 2024년 10월에 ID가 245인 사용자의 API 호출 횟수를 계산하려면, API 호출 시마다 해당 키에 PFADD커맨드를 사용하여 로그 식별자를 저장한다.
- PFCOUNT를 사용하면 중복되지 않은 데이터 수를 조회할 수 있다.
Geospatial Index를 이용한 위치 기반 애플리케이션 개발
위치 데이터란
- 사용자의 현재 위치를 파악한다.
- 사용자의 이동에 따라 실시간으로 위치를 업데이트한다.
- 사용자의 위치를 기준으로 근처 장소를 검색할 수 있다.
레디스에서의 위치 데이터
- Redis의 geo 자료 구조를 통해 공간 정보를 처리할 수 있다.
- 메모리에서 빠르게 계산할 수 있어, 다른 저장소보다 위치 데이터를 효율적으로 처리할 수 있다.
Geo 자료 구조 (geo set)
- 위치 공간 관리에 특화된 데이터 구조로, 각 위치 데이터는 경도와 위도의 쌍으로 저장된다.
- GEOADD 커맨드를 사용해 사용자의 현재 위치 데이터를 추가할 수 있다. (위치 변경 시에도 활용 가능)
- GEOPOS 커맨드로 저장된 위치 데이터를 조회할 수 있다.
- GEOSEARCH 커맨드로 특정 거리 내의 위치를 검색할 수 있다.
- BYRADIUS 옵션: 원 모양의 반경 내 위치를 찾는다.
- BYBOX 옵션: 가로/세로 값을 지정해 직사각형 범위 내 위치를 찾는다.
'Study Notes > 개발자를 위한 레디스' 카테고리의 다른 글
| [개발자를 위한 레디스] 6장 레디스를 메시지 브로커로 사용하기 (0) | 2025.11.15 |
|---|---|
| [개발자를 위한 레디스] 5장 레디스를 캐시로 사용하기 (0) | 2025.11.10 |
| [개발자를 위한 레디스] 3장 레디스 기본 개념 (1) | 2025.10.11 |
| [개발자를 위한 레디스] 2장 레디스 시작하기 (2) | 2025.08.27 |
| [개발자를 위한 레디스] 1장 마이크로서비스 아키텍처와 레디스 (0) | 2025.08.13 |